di Liliana Picciotto
 Quali sono le prospettive che il sistema Linked Open Data, appena adottato al CDEC, apre ai nostri orizzonti di storici? I metodi critici e analitici delle scienze umane si incontrano qui, ottimamente, con la prospettiva empirica della scienza, e una quantità di categorie possono essere messe in relazione fra loro, ed essere in grado di organizzare un numero pressoché illimitato di ordinamenti, che si accrescono a mano a mano che cresce l’universo dei data base correlati. Qui si tratta non solo di interloquire con i dati raccolti dal nostro Istituto, ma con altre enne ricerche che, sullo stesso argomento, possono essere state sviluppate in qualsiasi altra parte del mondo. Vi interessa sapere se un certo scienziato arrestato in Italia, prima di fuggire dall’Austria, aveva per caso depositato un brevetto a Vienna? Vi interessa sapere se di un certo profugo dalla Jugoslavia salvatosi in Italia esiste una fotografia catalogata in un archivio dell’attuale Croazia? E l’analisi di tale fotografia potrebbe rivelare che questa persona era un padre di famiglia e che quindi anche un bambino dovrebbe essere entrato in Italia e poi disperso!
Quali sono le prospettive che il sistema Linked Open Data, appena adottato al CDEC, apre ai nostri orizzonti di storici? I metodi critici e analitici delle scienze umane si incontrano qui, ottimamente, con la prospettiva empirica della scienza, e una quantità di categorie possono essere messe in relazione fra loro, ed essere in grado di organizzare un numero pressoché illimitato di ordinamenti, che si accrescono a mano a mano che cresce l’universo dei data base correlati. Qui si tratta non solo di interloquire con i dati raccolti dal nostro Istituto, ma con altre enne ricerche che, sullo stesso argomento, possono essere state sviluppate in qualsiasi altra parte del mondo. Vi interessa sapere se un certo scienziato arrestato in Italia, prima di fuggire dall’Austria, aveva per caso depositato un brevetto a Vienna? Vi interessa sapere se di un certo profugo dalla Jugoslavia salvatosi in Italia esiste una fotografia catalogata in un archivio dell’attuale Croazia? E l’analisi di tale fotografia potrebbe rivelare che questa persona era un padre di famiglia e che quindi anche un bambino dovrebbe essere entrato in Italia e poi disperso!
Questi esempi di ricerca, finora impraticabili in termini di fondi necessari e di tempo da impiegare per consultare archivi fisici, diventano ora possibili, facendoci vincere la battaglia contro la dispersione delle fonti. Nel prossimo futuro, si potrà creare una digital library esauriente, che rivoluzionerà il modo con cui si ha accesso e si naviga nelle rispettive storiografie.
Potremo un domani accedere ai dati su qualsiasi argomento, e costituire una tassonomia universale, da cui potrà scaturire una quantità infinita di storie non scritte.
La facilità di accesso permetterà, inoltre, nuove iniziative di analisi storiche, e il ricercatore avrà più tempo a disposizione per l’interpretazione e l’elaborazione dei materiali. Questo metodo smantellerà i recinti professionali e espanderà la gamma degli strumenti disponibili per scrivere la storia. Insomma, una vera rivoluzione del modo di trattare le nostre conoscenze, di cui fare tesoro.
Tutto questo ci dà la misura di quanta acqua sia passata davvero sotto i proverbiali ponti, da quando, negli Anni Settanta, Edgard Codd, lavorando alla IBM creò la teoria generale per la gestione delle banche dati su modello relazionale, e noi del CDEC, nella nostra stanzuccia nell’abbaino di Via Eupili 8 e ancora di più nella mia casa, di notte, spenta la luce nella stanza dei bambini, stavamo cercando il modo di trarre conclusioni possibili scartabellando a mano le 10.000 schede cartacee personali, messe in ordine alfabetico, che ci eravamo costruiti su ogni caso di ebreo deportato preso in esame. Si trattava di una ricerca di dati personali e di situazioni storiche sugli ebrei scomparsi nella Shoah, ricerca iniziata nell’immediato dopoguerra, che si stava protraendo negli anni.
La ricerca dei dati era basata su diverse fonti, anch’esse faticosamente reperite, tra le quali: i registri carcerari del biennio 1943-1945, i censimenti degli ebrei del 1938-1942 depositati nelle varie prefetture italiane, le testimonianze dei sopravvissuti, i “documenti per il rintraccio” emessi dalle varie questure, le relazioni sugli arresti effettuati da parte dei vari commissariati di PS o da parte delle varie tenenze dei carabinieri. Aggiungevamo a penna ogni dato faticosamente raccolto, su uno schedario originario che conteneva fogli cartacei, ognuno intestato ad un nome.
La storia del data base della Fondazione Cdec
Intuitivamente, chi aveva creato questa cartoteca prima di noi aveva capito che, per essere usata nel futuro, ogni suo foglio doveva contenere sempre le stesse caratteristiche: su una riga il cognome, sulla riga inferiore il nome, poi il luogo di nascita, la data di nascita, il luogo di residenza, il luogo dell’arresto, la data dell’arresto e così via. La semplice occhiata fissa su una certa riga, anche su un numero grandissimo di schede sfogliate, era il modo per poter ottenere dati riassuntivi utili a trarre conclusioni sulla ricerca stessa. Si scriveva poi su un foglietto per appunti: tot nomi, tot arrestati, tot bambini, tot donne, eccetera. Ci mettevamo giorni e giorni per dire quante persone erano state arrestate in quella data città: occorreva far scorrere, sotto uno sguardo attento, 10.000 fogli! Si sta parlando, è ovvio, della preistoria della possibilità globale di consultare uno schedario.
Potete immaginare la nostra gioia quando la ditta Olivetti, allora produttrice dei primi computer italiani, ci donò, agli inizi del 1980, un M20 e poi, a ruota, un M24 sul quale trasferire il contenuto di ogni foglio individuale, ricco di 32 righe, cioè di 32 caratteristiche per ciascuno. Anche il semplice caricamento dei dati è stato un lavoro immane di battitura e di interpretazione delle diverse scritture che comparivano sulle schede cartacee. Anche questo fu fatto grazie a fedeli amici: Franca Signorini e Gigliola Lopez ci si impegnarono con passione e dedizione.
Stavamo creando il nostro data base strutturato, in cui le informazioni contenute sarebbero state strettamente collegate fra loro da due brillanti laureandi in ingegneria informatica, Gianpaolo Sticotti e Alfonso Sassun, secondo il particolare modello logico relazionale inventato da Codd. Tutto era pienieristico: i due ragazzi venivano nella nostra sede dopo la giornata di studio, fuori orario. Si rimaneva in ufficio ogni giorno fino alle 10 di sera. Il data base girava in ambiente DB3 caricato su due floppy disk da 360 K. I nostri giovani, oggi, neanche saprebbero dire che cosa sono i K: o si parla di “tera” o non ci si capisce. Siamo in un ordine di grandezza da 100.000 a un miliardo e oltre!
Parliamo di un vero e proprio abaco, ma da quel momento, con grande sollievo, ci fu possibile gestire e organizzare efficientemente le notizie raccolte, cioè inserire, cancellare, aggiornare ciascun dato.
I nostri dati vennero suddivisi per argomenti in apposite caselle e poi tali argomenti suddivisi per categorie, cioè per campi, con la possibilità di porre quesiti che, in precedenza, non ci eravamo neanche sognati di porre.
Per esempio, quanti bambini di nome Dario, erano stati arrestati a Mantova il 1 aprile del 1944? Oppure: quante donne al di sopra dei 18 anni furono deportate ad Auschwitz nel mese di dicembre del 1943? A tali quesiti si rendeva ora possibile dare risposte.
Il vantaggio per la storiografia è apparso subito enorme, e non a caso Il libro della memoria, pubblicato per la prima volta nel 1991 che ne è scaturito, si è presentato come uno dei più preziosi in questo senso in Europa.
Si era ormai all’ultima decade del secolo scorso, e in tutte le comunità ebraiche nazionali d’Europa si era sviluppata la volontà di riuscire ad elencare le proprie vittime della Shoah, di passare dai numeri presunti alle persone, chiamandole nome per nome.
La “nominazione” è un topos culturale ebraico risalente all’epoca delle Crociate, quando dopo il passaggio delle spedizioni dirette verso Gerusalemme e i massacri di ebrei da esse perpetrati strada facendo, su grandi rotoli si scrivevano i nomi delle vittime, da leggere ogni anno.
La tassonomia delle vittime è, del resto, una modalità invalsa in tutto il mondo occidentale, si pensi al monumento per le vittime degli attentati alle torri gemelle a New York o al memoriale dei caduti in Vietnam a Washington.
Noi al CDEC eravamo molto avanti in questo lavoro, avevamo costruito una banca dati con tutte le notizie possibili raccolte su ciascuna vittima che, di fatto, rimane, per ricchezza, uno dei più completi d’Europa (aiutati in ciò anche dal fatto che il numero delle vittime e i numeri della stessa comunità ebraica italiana erano più limitati che altrove).
Non consideriamo chiusa la ricerca sulle vittime della Shoah, consci del fatto che sempre nuove fonti e dati emergono. Stranamente, con il passare del tempo, anziché scemare, le fonti si moltiplicano e si aprono nuove possibilità di ricerca: si pensi solo alla recente apertura dell’immensa fonte costituita dall’International Tracing Service della Croce Rossa ad Arolsen in Germania, oppure ai registri di stato civile dell’Isola di Rodi, per cui abbiamo solo ultimamente ottenuto il permesso di accesso. Ancora oggi, appoggiandoci all’impegno prezioso di Alberta Bezzan, abbiamo la possibilità di correggere i dati e di aumentarne il tasso di esattezza, un progetto di ricerca di cui sentiamo forte la missione e che ci tiene perennemente impegnati.
Da qualche anno, il CDEC ha intrapreso una ricerca analoga a quella sulle vittime, con l’obiettivo di descrivere con dati, sezionati e quantificabili, il salvamento degli scampati agli arresti e alle deportazioni. Questa ricerca è finanziata grazie ad un generoso grant della Viterbi Family Foundation. Conta su di uno staff dedicato, che raccoglie da varie fonti (per la maggior parte fonti dirette ottenute con interrogazione dei testimoni in audio-video) i dati e li carica su un sistema di data base correlati. Sono una cinquantina di tabelle per migliaia di categorie. Un sistema, programmato appositamente per il CDEC, da Gloria Pescarolo, da far tremare i polsi!
Liliana Picciotto
Per marcare il proprio sessantennale, il CDEC ha intrapreso una serie di iniziative: la pubblicazione di un nuovo portale basato sulla nuova tecnologia degli Linked Open Data (indirizzo: http://digital-library.CDEC.it); l’organizzazione di un workshop internazionale sugli Linked Open Data che si è svolto presso la Camera dei Deputati; una serie di conferenze sulla storia del CDEC organizzate dal Primo Levi Center di New York alle quali sono intervenuti il Presidente Giorgio Sacerdoti e Liliana Picciotto; la pubblicazione di un lungo saggio sul progetto di ricerca Memoria della salvezza che uscirà in inglese in primavera sulla prestigiosa rivista Holocaust and Genocide Studies; la presentazione dei progetti del CDEC presso l’Ambasciata italiana a Washington e presso l’Istituto Italiano di Cultura a New York, che valgono come un riconoscimento internazionale al CDEC in quanto centro studi dell’ebraismo italiano.
La digital
(r)evolution
del CDEC
Il CDEC apre i suoi archivi anche agli utenti del web: è forse questa la novità che meglio e più di altre segna e celebra i 60 anni di attività di questo istituto milanese che tanta parte ha avuto nello sviluppo degli studi sulla Shoah in Italia.
Inventari e documenti d’archivio, fotografie, interviste audio e video, l’intero catalogo della biblioteca… Il nuovo portale web CDEC Digital Library dedicato alle risorse degli archivi e della biblioteca del CDEC, apre una porta a chi, già dalla rete voglia cominciare ad esplorare il patrimonio del CDEC. Per ora ci siamo limitati a quello sulla storia e la memoria della Shoah; ma altre informazioni su altri argomenti della nostra storia degli ultimi 150 anni saranno disponibili (molto, in questo, dipende dai finanziamenti che riceveremo per continuare questa “digital ( r )evolution”).
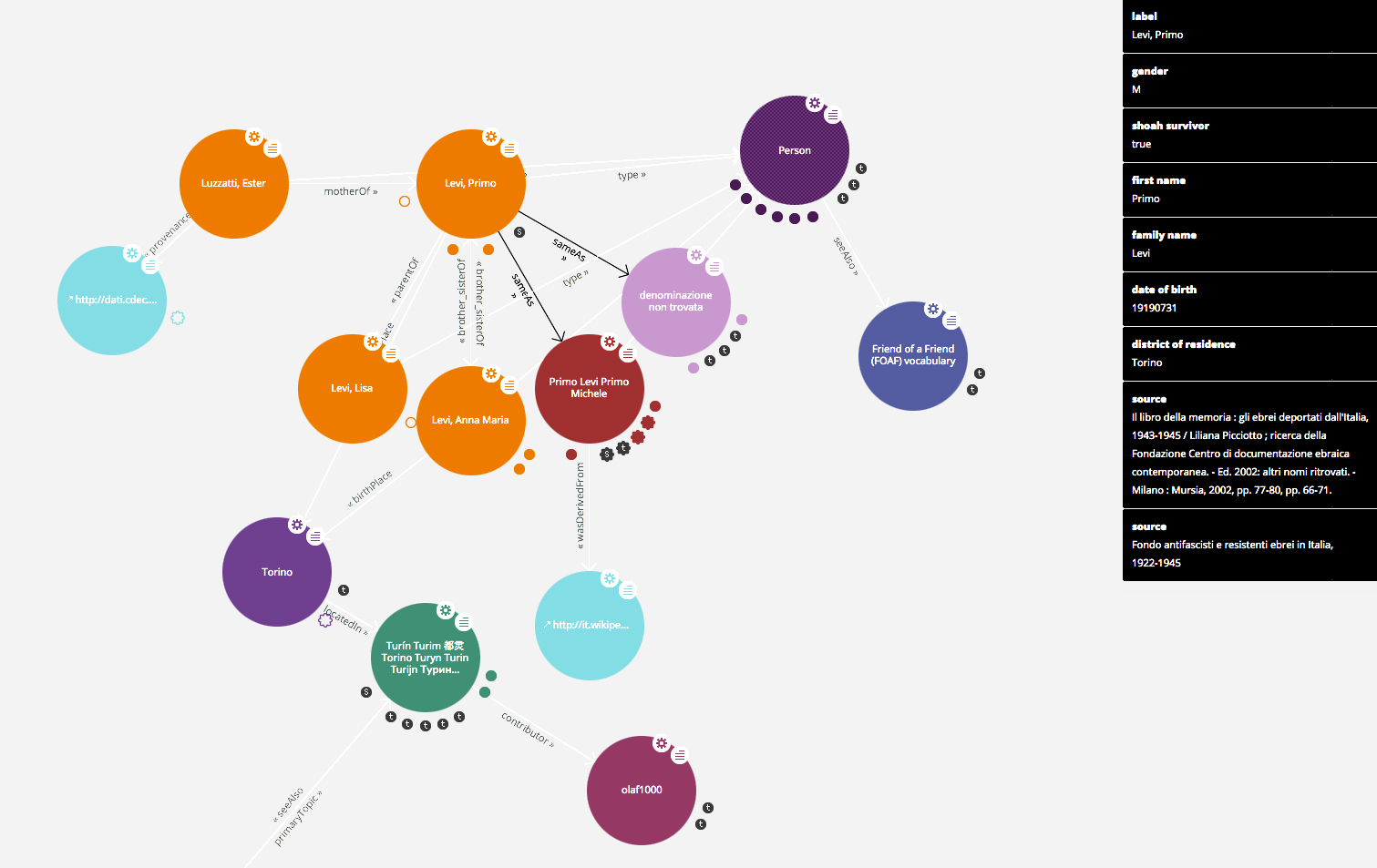
Cdec digital library è un portale nuovo dunque, ma anche innovativo perché la tecnologia che lo supporta e ne costituisce l’architettura è quella del Semantic Web. Grazie a questo il CDEC non solo è doverosamente passato al digitale, ma è anche entrato a pieno titolo nell’era del Web of Data – o Web of Things, come anche si usa dire. Con l’adozione dei Linked Open Data infatti abbiamo sia integrato e collegato semanticamente le informazioni provenienti dalle nostre numerose e sparse banche dati, sia collegato (e reso collegabile) la mole dei nostri dati, ai dati della Linked Data Cloud che alimentano il Web of Data. Per ora abbiamo pubblicato in formato LOD tutte le informazioni inerenti le vittime della Shoah in Italia: nomi, date e luoghi di nascita, nomi dei genitori, luoghi di residenza, luoghi e date di arresto, luoghi e date di internamento, convogli di deportazione, campi nazisti di deportazione, destino finale. Lo straordinario lavoro di ricerca, nome per nome, svolto dal CDEC e da Liliana Picciotto in particolare, sulle vittime della Shoah, è stato in questo modo valorizzato al suo massimo grado perché ogni singola informazione è come se fosse stata dotata di un “codice fiscale” che ne individua in maniera inequivocabile l’identità. I dati così trasformati sono oggi inclusi nella Linked Data Cloud: ciò fa sì che con un’unica interrogazione del motore di ricerca si possa accedere a tutte le informazioni disponibili attualmente nel web of data, su una certa persona, su un certo luogo, od oggetto. Non solo: i dati pubblicati in forma così granulare, sono riutilizzabili dagli utenti del web per sviluppare nuovi studi, nuove applicazioni e questo risponde appieno a una delle richieste più pressanti proveniente dal mondo della politica, dell’impresa, come anche dell’innovazione culturale: lavorare in maniera sinergica; condividere la conoscenza – per accrescere ed arricchire la conoscenza stessa; fare della cultura un bene realmente comune e democratico.
Il passaggio più oneroso di tutta questa operazione, sia in termini di risorse economiche e umane, sia in termini di tempo, è il collegamento di questi dati ai documenti digitalizzati e alle descrizioni archivistiche dei documenti. Ma è anche il passaggio che rende il nostro giacimento di documenti e informazioni, più ricco, accessibile, utilizzabile.
Laura Brazzo
{kind=link}